






The quantity and variation of data are important for the performance of most ML models (e.g. deep learning neural network models). Thus, the training of the neural network models requires a very large dataset. Then only it can achieve the accuracy expected in the production-ready model.
Assume that you have a small quantity of the dataset available which is not enough to train a model, and you don’t know how to generate a sufficient dataset with desired data variations. That is exactly what ‘data augmentation’ helps to achieve.
What is Data Augmentation?
Data Augmentation is a technique to artificially increase the volume of a dataset by adding certain variations to the existing dataset and adding it to the original dataset to generate ‘slightly modified and multiplied’ data. You can take all the samples available in the dataset and modify them several times in a different way to get the larger dataset.
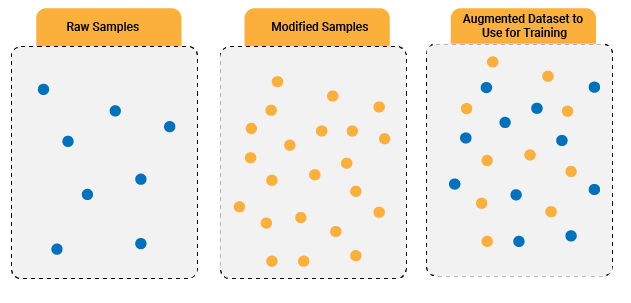
Importance of the Dataset in Model Training
The very first stage of the machine learning pipeline is to generate or acquire the required dataset that is used to train the machine learning model. The machine learning models are smart enough to recognize the objects for which they are trained. But they are not so smart to take care of the different scenarios if they are not part of the training.
For example, if the model is trained with all the training images aligned in only one specific direction, then it may fail to recognize the object in the horizontally and/or vertically flipped images. The reason for this is that the features it produces are different from the features it has learned during the training, even though they belong to the same object.
In most scenarios, the availability of quality data is always a big question. It may be available in small quantities or may not be available at all. In such cases, it would be a challenge to collect a dataset that is sufficient enough to achieve the desired accuracy. If the dataset is not available in sufficient quantity or with the desired level of variations then it may result in either underfitting or overfitting.
Why is Data Augmentation Important?
Collecting and labeling data is a tedious and costly process in machine learning models. Data augmentation can transform into datasets that help organizations to reduce operational costs. At the same time, it solves the problem of limited dataset size and limited data variation. This improves the overall performance of the model in various scenarios.
How Does it Work?
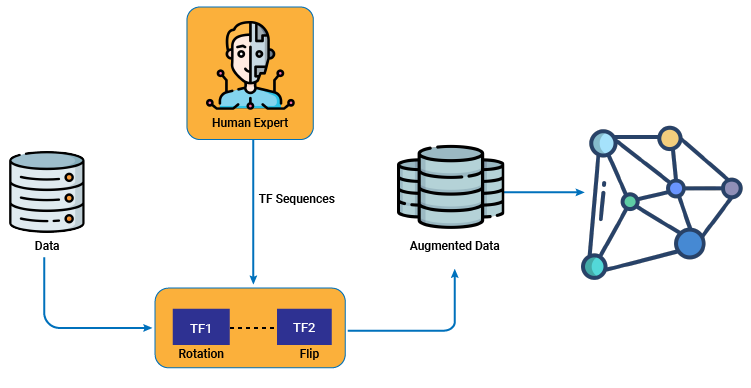
(Heuristic data augmentations applied on transformation functions tuned by human experts).
Based on the type of dataset, different data augmentation techniques can be used. There are many data augmentation techniques available for the image/video, audio, and text data. We will explore the image/video data augmentation method in detail.
Data Augmentation Techniques in Image/Video
The image/video stores RGB information in 2D arrays. The primary data augmentation techniques could be changing the orientation of the images, changing the resolution/size of the images, and changing the RGB (pixel) values.
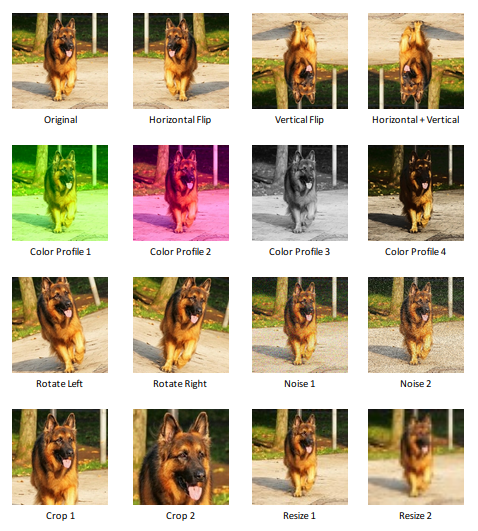
Different combinations of these options can lead to many more augmentation methods. The imgaug library provides a number of different image data augmentation options which are listed below.
- Arithmetic:- This category of operations changes the pixel values of the whole image or some parts of it. The addition and multiplication options add and multiply the pixel values by a random number (generated within a predefined range). This number could be the same for all pixels or different for neighboring pixels. There are options that set the random pixels or clusters of pixels to a constant value. The similar options are to add certain noise to the whole image. Also, inverting the pixel values is available
- Artistic:- This category offers an option to convert the style of the image into a cartoonish image
- Blur:- This category offers different options to blur the image contents. The possible options are GaussianBlur, AverageBlur, MedianBlur, BilateralBlur, MotionBlur, MeanShiftBlur
- Color:- This category of operations targets color space, brightness, hue and saturation. An example of the color space option is to convert RGB to HSV, then add a random value (uniformly sampled per image) to the Hue channel, and convert back to RGB. There are options to perform the addition and the multiplication operations on the brightness, the saturation, and the hue.
- Contrast:- This category of operations is dedicated to contrast manipulation. The available options are Gamma contrast, Sigmoid contrast, Logarithmic contrast, Linear contrast
- Convolutional:- As the name implies, this category of operations is related to convolving images with predefined matrix values. It offers options to change sharpness, add an emboss effect, and detect edges in the image
- Flip:- This is a widely used option, and it has options to flip the images horizontally and/or vertically
- Geometric:- This category of operations can scale the image (like zoom in and zoom out), shift the image (horizontally and/or vertically) and add padding to the opposite end of the image, and rotate the image
- Imgcorruptlike:- This category of options adds different noise to the image, like Gaussian noise, Shot noise, Impulse noise, Speckle noise. It also offers different image blur options like Gaussian blur, Glass blur, Defocus blur, Motion blur, Zoom blur. Additionally, fog, frost, snow, and spatter effects can also be applied
- Size:- This category of options performs operations related to the size of the image. The image can be resized based on specific height and width or based on the percentage of resize. The cropping and padding of the image can be applied to the specific size of the image
The image data augmentation certainly improves the accuracy of the model, by generating the desired level of a dataset.
At VOLANSYS, our teams are specialized in machine learning services to build optimized machine learning model across multiple data types, including image, video, speech, audio, and texts for end user applications like security, preventive maintenance, audio/video analytics, and many more, thus making us a preferred partner for machine learning services.
Read our success stories relating to machine learning services here.

About the Author: Aekam Parmar
Aekam Parmar is associated with VOLANSYS Technologies as Principal Engineer. He has 10+ years of experience working on different bare metal and Linux based projects, which includes RFID system, Video Surveillance system, Digital Taxi Meter, Smart Lighting solution (IoT) and more. He is a Machine Learning enthusiast as well and like to explore this domain in depth

